
Introduction
This review covers “Mastering Serverless Computing for Data Science – AI-Powered Course,” a digital learning product that promises to teach serverless computing with AWS Lambda, deploying ML pipelines, and managing applications without worrying about infrastructure. Below I provide a structured, objective, and practical assessment of the course: what it is, how it looks and feels, the features it emphasizes, real-world usage scenarios, strengths and weaknesses, and a final verdict to help potential buyers decide whether it fits their goals.
Overview
Product: Mastering Serverless Computing for Data Science – AI-Powered Course
Manufacturer / Provider: Not specified in the product data — the listing does not identify a specific training provider or platform. If you are considering purchase, verify the provider, their reputation, and refund/credential policies before enrolling.
Product category: Online technical course / professional training (focus: serverless architecture for data science and ML workflows).
Intended use: Learn how to design, build, and operate serverless data and ML pipelines (with a focus on AWS Lambda per the description), deploy models and applications, and manage the run-time and costs of serverless systems so data scientists and engineers can deliver production-ready insights without managing servers.
Appearance, Materials & Aesthetic
As a digital course, “appearance” refers to the course interface, learning materials, and pedagogical design rather than a physical product. Based on the product title and description, typical components you should expect include:
- Video lectures (short, topic-focused modules) with slide decks and instructor narration.
- Hands-on code notebooks (likely Jupyter or similar) for step-by-step exercises — these are commonly used in data science courses and are the most practical format for running examples locally or in cloud lab environments.
- Downloadable resources: architecture diagrams, cheat sheets, IaC (Infrastructure as Code) templates or sample CloudFormation/Terraform snippets, sample datasets, and GitHub repos.
- Interactive labs or cloud-based sandboxes to try deploying serverless functions and pipelines (if the provider includes cloud lab access).
- Assessments: quizzes, coding challenges, and project assignments to validate learning.
Unique design elements you should look for (the product is described as AI-powered):
- AI-assisted learning paths — adaptive recommendations or tailored module sequencing based on your progress.
- Automated code checks, feedback, or code generation for quick prototyping of Lambda handlers, deployment scripts, or pipeline components.
- Searchable examples and contextual help driven by NLP (for faster concept lookups).
Note: Since the provider is not specified, confirm whether AI features are integrated into the course platform itself or implemented as optional tools/code snippets you run locally.
Key Features & Specifications
From the title and description, the course emphasizes the following features and topics:
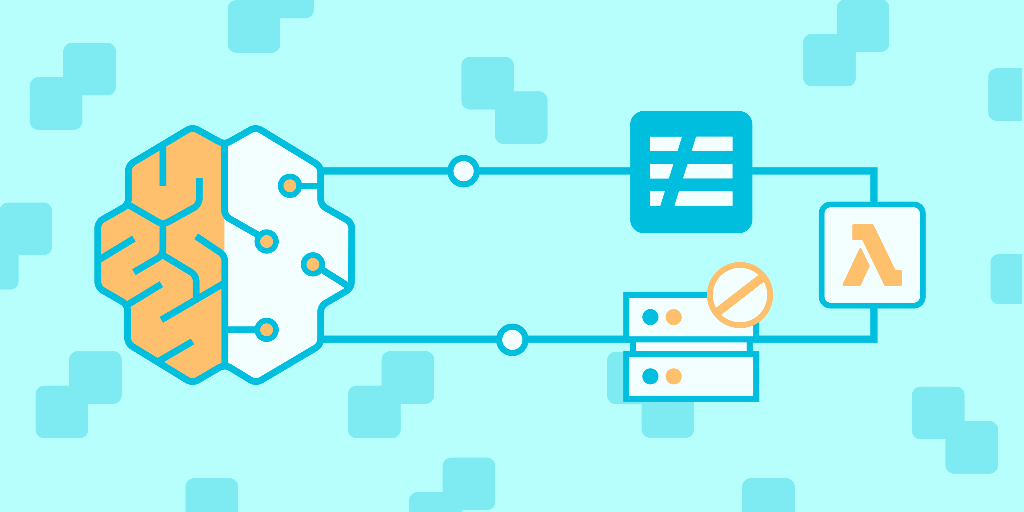
- AWS Lambda-centric serverless architecture: Understanding function-as-a-service, invocation models, triggers and event sources.
- ML pipeline deployment: Packaging, deploying, and orchestrating data processing and ML model inference tasks in a serverless environment.
- Serverless application management: Monitoring, logging, error handling, scaling behavior, and cost control in serverless deployments.
- Hands-on labs and demos: Practical examples of building and deploying serverless pipelines and services (commonly with sample datasets).
- AI-powered learning aids: Personalization, guided exercises, or automated feedback (based on the “AI-Powered” label).
- Common supporting services (likely covered): API Gateway, S3, Step Functions, DynamoDB or other lightweight storage, IAM and security best practices.
- Languages & tooling (typical): Python is the most common language in data science courses; expect CLI and SDK examples (AWS CLI, boto3), containerization notes for packaging heavy models, and possibly IaC templates.
- Format: Most courses like this are self-paced and modular; confirm number of modules, total hours, and certification/assessment details with the provider.
Experience Using the Product (Practical Scenarios)
1. Getting started (novice data scientist)
The early modules should be approachable for someone with basic Python and ML knowledge. Expect guided walkthroughs that explain:
- What serverless means in practice (deployment vs. infrastructure).
- How to set up a minimal AWS account and permissions (or how to use a provided sandbox).
- Simple Lambda functions to process data stored in S3 or run light-weight model inference.
Strength: lowers the barrier to deploying simple models without provisioning servers. Caveat: you will need to become familiar with cloud consoles, IAM, and cost-awareness to avoid surprises.
2. Building ML inference pipelines
In intermediate scenarios, the course should cover orchestrating multiple serverless components to create an inference pipeline: event ingestion (S3, streams), transformation (Lambda), orchestration (Step Functions or equivalent), and lightweight storage. The hands-on labs are where you’ll learn practical concerns: packaging model artifacts, handling cold starts, optimizing memory & timeout settings, and logging for observability.
Strength: good for rapid prototyping and low-to-medium throughput inference. Limitation: long-running model training or very large models often require hybrid approaches (batch jobs on managed compute or containers).
3. Production and scale considerations
For production workloads, the course should address monitoring, error handling, retries, idempotency, and cost management. Realistic lessons include dealing with rate limits, concurrency, cold starts, vendor locking and how to design idempotent serverless functions.
Strength: provides a serverless-first approach for many production use cases. Weakness: serverless imposes architectural constraints (time limits, ephemeral storage, and concurrency caps) that require alternative strategies for heavy-duty model serving and feature stores.
4. Team training and collaboration
The course can serve as a useful onboarding resource for data teams adopting serverless patterns. If the AI features include code review or automated hints, they can accelerate learning. Ensure the course covers reproducibility (versioning code and models), CI/CD, and cost-accounting to be team-ready.
Pros
- Focuses on a practical and increasingly popular approach to deploying ML and data-processing workloads without managing servers.
- Hands-on labs and deployable examples (assumed in such courses) accelerate the transition from theory to practice.
- AI-powered learning features (if well implemented) can personalize learning, provide instant feedback, and speed up debugging and prototyping.
- Specifically calling out AWS Lambda makes the course concrete: learners get actionable skills for a widely used serverless platform.
- Useful for data scientists who want to ship models faster with fewer operations responsibilities.
Cons
- Provider details, syllabus depth, pricing, and total duration are not specified in the product data — confirm these before purchase.
- Serverless has intrinsic limits (execution time, memory, ephemeral storage) that reduce suitability for large-batch training or very large models — the course must cover hybrid strategies if you expect to do that.
- Potential vendor lock-in: focusing on AWS Lambda and associated services can make migration to another cloud more work; the course should teach patterns to minimize lock-in, but this varies by provider.
- AI-powered features are labeled but the degree of usefulness depends on implementation quality — some platforms’ “AI” features are basic or gimmicky.
- Hands-on labs that require a live AWS account can incur cloud costs; confirm whether cloud lab credits or sandbox access are provided.
Recommendations & Tips Before Buying
- Verify the course provider, instructor credentials, and recent updates (serverless and AWS evolve quickly).
- Check whether the course provides GitHub repos, IaC templates, and lab sandboxes or cloud credits.
- Confirm prerequisites: likely Python, basic ML concepts, and some familiarity with cloud consoles/CLI.
- Look for sample lesson videos and a detailed syllabus to ensure it covers operational topics (monitoring, security, testing) and not just demos.
- Ask whether AI features include code validation, adaptive quizzes, or code generation and see demos if possible.
Conclusion
“Mastering Serverless Computing for Data Science – AI-Powered Course” targets a valuable intersection: enabling data scientists to deploy and operate ML pipelines using serverless architectures. The course’s strengths are its practical, deployment-focused approach and the promise of AI-powered learning aids that can speed up comprehension and prototyping. However, the product listing lacks essential provider and syllabus details, so prospective buyers should confirm those points and ensure the curriculum covers operational realities (cold starts, timeouts, observability, cost control) and hybrid patterns for heavier workloads.
Overall impression: If the course is delivered by a reputable provider and includes comprehensive, up-to-date hands-on labs and real AI-powered assistance, it will be a strong, practical choice for data scientists and engineers who want to adopt serverless patterns for inference and lightweight data processing. If you need to handle large-scale training jobs or very large models, treat serverless as one tool in a broader production strategy rather than a universal solution.
Final recommendation: Investigate provider details, confirm lab and AI-assisted features, and ensure the syllabus aligns with your team’s production needs before enrolling.
Leave a Reply